

APACHE SPARK VÀ TẦM QUAN TRỌNG TRONG BIG DATA
Trong thế giới công nghệ hiện đại, nơi dữ liệu khổng lồ chảy không ngừng, khả năng xử lý và phân tích thông tin nhanh chóng, hiệu quả là chìa khóa thành công cho mọi tổ chức. Từ những tập đoàn lớn đến các doanh nghiệp vừa và nhỏ, tất cả đều cần một công cụ mạnh mẽ để khai thác giá trị từ kho tàng dữ liệu của mình. Và đó chính là lúc Apache Spark tỏa sáng như một giải pháp toàn diện, mang đến sức mạnh đột phá trong lĩnh vực Big Data.

Apache Spark là gì?
Hãy hình dung Apache Spark như một cỗ máy siêu tốc được thiết kế để xử lý dữ liệu ở quy mô lớn. Đây là một framework mã nguồn mở, cho phép bạn lập trình các hệ thống máy tính hoạt động song song, đảm bảo ngay cả khi có lỗi xảy ra, công việc vẫn được tiếp tục. Spark ra đời tại Đại học California Berkeley và sau đó được hiến tặng cho Apache Software Foundation, nơi nó tiếp tục được phát triển và hoàn thiện.
Sức mạnh xử lý phân tán của Apache Spark chính là yếu tố làm nên tầm quan trọng của nó trong Big Data và Học máy (Machine Learning). Những lĩnh vực này đòi hỏi khả năng tính toán khổng lồ để xử lý các bộ dữ liệu đồ sộ. Điều tuyệt vời là Spark còn đơn giản hóa việc lập trình, giúp các nhà phát triển dễ dàng làm việc với dữ liệu lớn mà không cần bận tâm quá nhiều đến những phức tạp kỹ thuật.

Apache Spark là một framework xử lý dữ liệu mã nguồn mở trên quy mô lớn
Các thành phần cốt lõi của Apache Spark
Apache Spark được xây dựng trên một kiến trúc module linh hoạt, gồm 5 thành phần chính, mỗi thành phần đóng một vai trò quan trọng trong việc xử lý dữ liệu:
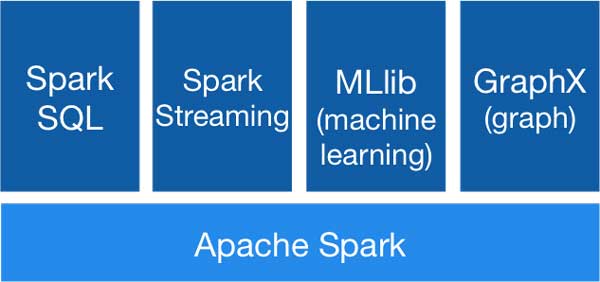
Apache Spark gồm: Spark Core, Spark Streaming, Spark SQL, MLlib và GraphX
Spark Core: Trái tim của hệ thống
Spark Core là nền tảng của mọi hoạt động trong Apache Spark. Nó đảm nhiệm việc tính toán và xử lý dữ liệu trực tiếp trong bộ nhớ, mang lại tốc độ vượt trội. Đồng thời, Spark Core còn kết nối với các hệ thống lưu trữ bên ngoài, đảm bảo dữ liệu luôn sẵn sàng cho mọi tác vụ.
Spark SQL: Sức mạnh cho dữ liệu có cấu trúc
Nếu bạn đã quen với việc truy vấn dữ liệu bằng SQL, Spark SQL sẽ là người bạn đồng hành lý tưởng. Nó tập trung vào xử lý dữ liệu có cấu trúc, cho phép các nhà phân tích và nhà phát triển dễ dàng truy vấn dữ liệu bằng cú pháp SQL quen thuộc. Ngoài ra, Spark SQL còn hỗ trợ đọc và ghi dữ liệu từ nhiều nguồn khác nhau như JSON, HDFS, Apache Hive, và nhiều hơn nữa.
Spark Streaming: Xử lý dữ liệu thời gian thực
Trong thế giới kinh doanh hiện đại, việc phân tích dữ liệu ngay lập tức là vô cùng quan trọng. Spark Streaming cho phép Apache Spark xử lý dữ liệu theo thời gian thực hoặc gần như thời gian thực. Nó chia nhỏ dòng dữ liệu thành các gói nhỏ liên tục, sau đó xử lý chúng bằng API của Spark, giúp doanh nghiệp phản ứng nhanh chóng với mọi thay đổi.
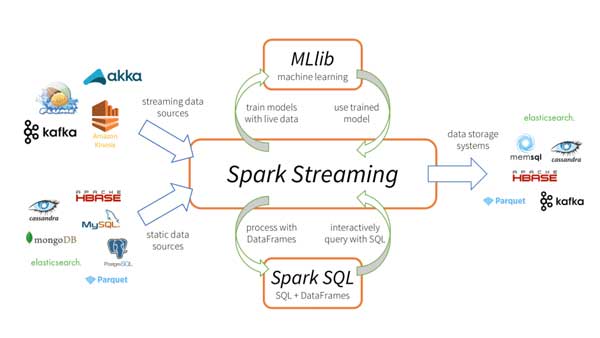
Spark Streaming giúp Apache Spark đáp ứng các yêu cầu xử lý thời gian thực
MLlib (Machine Learning Library): Thư viện học máy phân tán
MLlib là thư viện học máy mạnh mẽ của Spark, được xây dựng để chạy trên kiến trúc phân tán. Điều này có nghĩa là bạn có thể xây dựng và triển khai các mô hình học máy phức tạp trên các tập dữ liệu khổng lồ một cách nhanh chóng. Theo nhiều so sánh, MLlib thậm chí còn nhanh hơn đáng kể so với các thư viện học máy truyền thống trên Hadoop.
GraphX: Khám phá thế giới đồ thị phức tạp
GraphX là công cụ tuyệt vời để xử lý dữ liệu dạng đồ thị, giúp bạn phân tích các mối quan hệ phức tạp giữa các điểm dữ liệu. Nó cung cấp các thuật toán phân tán chuyên biệt, tận dụng sức mạnh của Spark Core để mô hình hóa và truy vấn dữ liệu đồ thị một cách hiệu quả.
Kiến trúc mạnh mẽ của Apache Spark
Về mặt kiến trúc, Apache Spark hoạt động dựa trên hai thành phần chính: trình điều khiển (driver) và trình thực thi (executors). Trình điều khiển có nhiệm vụ biến đổi các yêu cầu của người dùng thành các tác vụ nhỏ, sau đó phân phối chúng đến các nút xử lý (worker nodes). Các trình thực thi sẽ chạy trên các nút này và hoàn thành các tác vụ được giao.
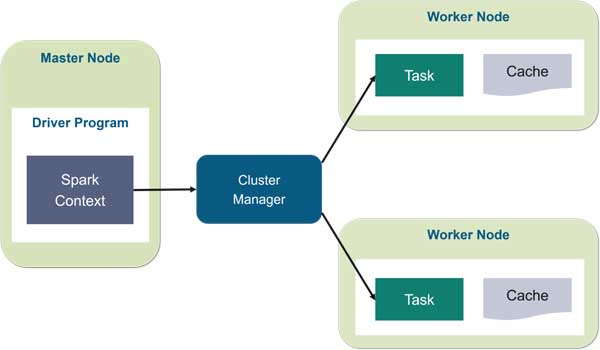
Apache Spark gồm hai thành phần trình điều khiển và trình thực thi
Spark cũng có thể chạy độc lập, nhưng việc sử dụng các công cụ quản lý cụm như Apache Mesos, Kubernetes hay Docker Swarm sẽ giúp tối ưu hóa tài nguyên và tăng cường hiệu quả. Mọi lệnh xử lý dữ liệu trong Spark đều được xây dựng thành Đồ thị vòng có hướng (DAG), một lớp lập lịch thông minh giúp Spark xác định chính xác nhiệm vụ nào cần thực hiện trên nút nào và theo trình tự ra sao.
Vì sao Apache Spark là lựa chọn hàng đầu cho Big Data?
Apache Spark không chỉ là một công cụ, mà là một bước tiến vượt bậc trong xử lý dữ liệu lớn. Dưới đây là những lý do khiến Spark trở thành người bạn đồng hành không thể thiếu của mọi doanh nghiệp:
Tốc độ xử lý vượt trội
Apache Spark được thiết kế để mang lại hiệu suất tối đa. Nó có thể xử lý dữ liệu nhanh hơn tới 100 lần so với Hadoop truyền thống, nhờ khả năng tính toán trên bộ nhớ và các tối ưu hóa thông minh khác. Ngay cả khi dữ liệu được lưu trữ trên đĩa, Spark vẫn duy trì tốc độ ấn tượng, giữ kỷ lục thế giới về phân loại dữ liệu quy mô lớn trên đĩa.
Dễ dàng sử dụng và phát triển
Spark nổi bật với các API thân thiện, dễ sử dụng, giúp các nhà phát triển làm việc với các tập dữ liệu lớn một cách thuận tiện. Với hơn 100 toán tử chuyển đổi dữ liệu và API DataFrame quen thuộc cho dữ liệu bán cấu trúc, Spark giúp bạn tập trung vào việc giải quyết bài toán thay vì đối phó với sự phức tạp của hệ thống.
Hệ sinh thái thư viện phong phú
Spark đi kèm với một bộ thư viện cấp cao tích hợp sẵn, bao gồm hỗ trợ truy vấn SQL, xử lý luồng dữ liệu trực tuyến, học máy và phân tích đồ thị. Những thư viện tiêu chuẩn này không chỉ tăng năng suất làm việc của nhà phát triển mà còn có thể kết hợp liền mạch, tạo ra các quy trình xử lý dữ liệu phức tạp một cách dễ dàng.
Apache Spark không chỉ là một công cụ xử lý dữ liệu, mà là một nền tảng vững chắc giúp các doanh nghiệp biến dữ liệu thô thành những hiểu biết sâu sắc và hành động cụ thể. Với tốc độ, sự linh hoạt và hệ sinh thái mạnh mẽ, Spark thực sự là một người khổng lồ trong thế giới Big Data, mở ra cánh cửa đến vô vàn cơ hội phát triển trong tương lai.
Khám phá thêm về chương trình đào tạo Kỹ sư Dữ liệu tại TechData.AI để nắm bắt cơ hội làm chủ công nghệ tiên tiến này.

MagicFlow | TechData.AI