

Kafka được sử dụng bởi hơn 80% trong số 100 công ty trong danh sách Fortune và là một trong những nền tảng xử lý luồng dữ liệu phổ biến nhất trong ngành hiện nay. Kafka được hàng nghìn tổ chức hàng đầu thế giới sử dụng cho các đường ống dẫn dữ liệu hiệu suất cao, phân tích luồng, tích hợp dữ liệu và nhiều ứng dụng quan trọng khác.
Kafka là gì?
Apache Kafka là một nền tảng phát trực tuyến sự kiện phân tán mã nguồn mở. Apache Kafka được xây dựng nhằm mục đích xử lý dữ liệu streaming real-time (theo thời gian thực). Nói một cách đơn giản - Apache Kafka được phát triển để lưu trữ các streams of records (luồng ghi dữ liệu).
Ngày nay, hàng tỷ nguồn dữ liệu liên tục tạo ra các luồng data record, bao gồm các luồng sự kiện. Một sự kiện là một bản ghi kỹ thuật số về một hành động đã xảy ra và thời gian nó xảy ra. Thông thường, một sự kiện là một hành động thúc đẩy một hành động khác như một phần của quy trình. Một khách hàng đặt hàng, chọn chỗ ngồi trên chuyến bay, hoặc gửi đơn đăng ký đều là những ví dụ về các sự kiện. Một sự kiện không nhất thiết phải liên quan đến một người — ví dụ: báo cáo của máy điều nhiệt được kết nối về nhiệt độ tại một thời điểm nhất định cũng là một sự kiện.
Các luồng này tạo cơ hội cho các ứng dụng phản hồi dữ liệu hoặc sự kiện trong thời gian thực. Nền tảng stream dữ liệu cho phép các nhà phát triển xây dựng các ứng dụng liên tục sử dụng và xử lý các luồng này ở tốc độ cực cao, với mức độ trung thực và chính xác cao dựa trên thứ tự xuất hiện chính xác của chúng.

LinkedIn đã phát triển Kafka vào năm 2011 như một message broker thông lượng cao để sử dụng cho chính nó, sau đó Kafka có nguồn mở và được donate cho Software Foundation. Kafka sử dụng ngôn ngữ chính là Java hoặc Scala.
Ngày nay, Kafka đã phát triển thành nền tảng stream dữ liệu phân tán được sử dụng rộng rãi nhất, có khả năng nhập và xử lý hàng nghìn tỷ bản ghi mỗi ngày mà không có bất kỳ độ trễ hiệu suất có thể nhận thấy nào theo quy mô khối lượng. Các tổ chức trong danh sách Fortune 500 như Target, Microsoft, AirBnB và Netflix dựa vào Kafka để cung cấp trải nghiệm theo thời gian thực, theo hướng dữ liệu cho khách hàng của họ.
Ưu, nhược điểm nổi bật của Kafka
Một số ưu và nhược điểm nổi bật của Kafka cụ thể như sau:
Ưu điểm của Kafka
- Open-source
- High-throughput: Có khả năng xử lý một lượng lớn thông tin một cách liên tục, gần như không có thời gian chờ
- High-frequency: Có thể xử lý cùng lúc nhiều message và nhiều thể loại topic
- Scalability: Dễ dàng mở rộng khi có nhu cầu
- Tự động lưu trữ message, dễ dàng kiểm tra lại
- Cộng đồng người dùng đông đảo, được hỗ trợ nhanh chóng khi cần
Nhược điểm của Kafka
- Chưa có bộ công cụ giám sát hoàn chỉnh: Có nhiều tool khác nhau nhưng mỗi tool chỉ đáp ứng một tính năng quản lý nhất định, chẳng hạn như: Kafka tool (offset manager) GUI tool - quản lý topic và consumer, Lense - hỗ trợ query message, Akhq - toolbox quản lý Kafka và view data bên trong Kafka
- Không chọn được topic theo wildcard: Người dùng sẽ cần phải sử dụng chính xác tên topic để xử lý message
- Giảm hiệu suất: Kích thước message tăng khiến cho consumer và producer phải compress và decompress message, từ đó làm bộ nhớ bị chậm đi, ảnh hưởng đến throughput và hiệu suất.
- Xử lý chậm: Đôi khi số lượng queues trong Kafka cluster tăng đột biến khiến Kafka xử lý chậm hơn.
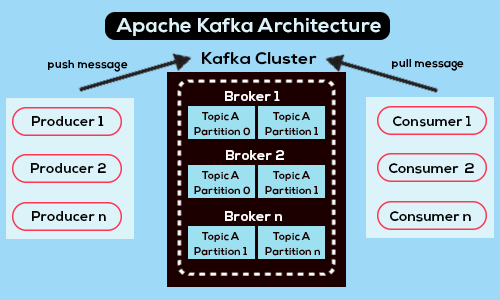
Cơ chế hoạt động của Kafka
Apache Kafka hoạt động giống như một message queue (hàng đợi message) pub-sub truyền thống (chẳng hạn như RabbitMQ) ở chỗ nó cho phép bạn publish và subscribe các luồng message. Tuy nhiên Apache Kafka khác với message queue truyền thống ở 3 điểm chính:
- Kafka hoạt động như một hệ thống phân tán hiện đại chạy dưới dạng một cụm và có thể mở rộng quy mô để xử lý bất kỳ số lượng ứng dụng nào.
- Kafka được thiết kế để phục vụ như một hệ thống lưu trữ và có thể lưu trữ dữ liệu trong thời gian cần thiết; hầu hết các message queue sẽ xóa message ngay sau khi consumer xác nhận đã nhận.
- Kafka xử lý stream processing, tính toán các luồng dẫn xuất và các dataset một cách linh hoạt, thay vì chỉ chuyển các dãy thông báo.
Quy trình làm việc của Pub-Sub Messaging
Sau đây là quy trình từng bước của Pub-Sub Messaging:
- Các producer gửi message đến một topic theo định kỳ.
- Kafka broker lưu trữ tất cả các message trong các partition được định cấu hình cho topic cụ thể đó. Nó đảm bảo các message được chia đều giữa các partition. Nếu producer gửi hai message và có hai partition, Kafka sẽ lưu trữ một message trong partition đầu tiên và message thứ hai trong partition thứ hai.
- Consumer sẽ subscribe một topic cụ thể.
- Sau khi consumer đã subscribe một topic, Kafka sẽ cung cấp offset hiện tại của topic cho consumer và cũng lưu offset trong nhóm Zookeeper.
- Consumer sẽ yêu cầu Kafka trong một khoảng thời gian đều đặn (ví dụ 100 Ms) cho các message mới.
- Khi Kafka nhận được message từ producer, nó sẽ chuyển tiếp những message này đến consumer.
- Consumer sẽ nhận được message và xử lý nó.
- Sau khi message được xử lý, consumer sẽ gửi xác nhận đến Kafka broker.
- Khi Kafka nhận được xác nhận, nó sẽ thay đổi offset thành giá trị mới và cập nhật nó trong Zookeeper. Vì các offset được duy trì trong Zookeeper nên consumer có thể đọc message tiếp theo một cách chính xác ngay cả khi máy chủ gặp sự cố.
- Luồng trên sẽ lặp lại cho đến khi consumer dừng yêu cầu.
- Consumer có tùy chọn tua lại/bỏ qua offset mong muốn của một topic bất kỳ lúc nào và đọc tất cả các message tiếp theo.
Một số khái niệm cơ bản trong Kafka
Để làm việc với Kafka, các bạn cần nắm một số khái niệm cơ bản về:
1. Producer
Producer là những application produce data và gửi data tới Kafka Server. Data này sẽ là những message có định dạng, được gửi dưới dạng mảng byte tới Kafka server. Ví dụ như các bạn có một tập tin .txt chứa text bên trong, chúng ta có thể dùng Producer để đọc từng dòng trong tập tin này rồi gửi tới Kafka server.
2. Consumer
Kafka sử dụng consumer để subscribe vào topic, các consumer được định danh bằng các group name. Nhiều consumer có thể cùng đọc một topic. Sau khi nhận được data, Consumer có thể thêm code để xử lý data theo nhu cầu của mình.
3. Cluster
Kafka cluster là một set các server, mỗi một set này được gọi là 1 broker.
4. Broker
Broker là Kafka server, là cầu nối giữa Message Publisher và Message Consumer, giúp chúng có thể trao đổi message với nhau.
5. Topic
Dữ liệu truyền trong Kafka theo topic, khi cần truyền dữ liệu cho các ứng dụng khác nhau thì sẽ tạo ra các topic khác nhau.
6. Partitions
Kafka là một distributed messaging system và chúng ta có thể setup Kafka server với cluster. Trong trường hợp một topic nhận quá nhiều message tại cùng một thời điểm, chúng ta có thể chia topic này thành những partitions được share giữa các Kafka server với nhau trong một cluster được handle các message này.
Một partition sẽ small và independent với các partitions khác. Số lượng partition cho mỗi topic thì tuỳ theo nhu cầu của ứng dụng mà chúng ta có thể quyết định.
7. Consumer Group
Consumer group là một group các Consumer consume message từ Kafka server. Mỗi một Consumer Group sẽ share với nhau việc handle message.
8. ZOOKEEPER: dùng để quản lý và bố trí các broker.
Tìm hiểu về ứng dụng của Kafka
Nhờ khả năng xử lý hiệu quả và lưu trữ dữ liệu lớn theo thời gian thực, Kafka được các doanh nghiệp thuộc nhiều lĩnh vực khác nhau tin tưởng để sử dụng cho hệ thống của họ. Cùng tìm hiểu về ứng dụng của Kafka đối với người dùng nhé!
Đóng vai trò như message broker
Người dùng có thể sử dụng Kafka để thay thế cho các Message broker, ví dụ như ActiveMQ hoặc RabbitMQ.
Quản lý hoạt động website
Đây là cách thức truyền thống để sử dụng Kafka, được dùng để xây dựng website và đăng tải nội dung theo thời gian thực. Các dữ liệu như lượt xem trang, hoạt động tìm kiếm… đều được tạo thành các topic. Việc quản lý hoạt động này giúp bạn phân tích hành vi của người dùng trên trang tốt hơn, từ đó thu hút được nhiều người đọc hơn.
Đo lường
Kafka cũng có thể được dùng để xây dựng dữ liệu giám sát các hoạt động. Điều này đồng nghĩa với việc tập hợp số liệu thống kê từ nhiều nguồn phân tán trên trang để tạo ra một nguồn dữ liệu tổng hợp.
Tạo log
Kafka hỗ trợ tổng hợp log hoặc nhật ký hoạt động, tóm tắt các chi tiết và cung cấp bản ghi cụ thể về dữ liệu sự kiện nhằm phục vụ cho việc xử lý trong tương lai.
Stream processing
Steam processing là cách sử dụng phổ biến hiện nay của Kafka, hệ thống được phát triển để xử lý dữ liệu theo thời gian thực. Mỗi khi dữ liệu mới được thêm vào topic, thì sẽ được ghi vào hệ thống ngay lập tức và truyền đến bên nhận dữ liệu. Hơn nữa, thư viện Kafka Streams được tích hợp từ phiên bản 0.10.0.0 có tính năng xử lý stream nhẹ nhưng rất mạnh mẽ.
Kết luận
Trong quá trình phát triển website, ứng dụng rất dễ xảy ra trường hợp lượng message cần xử lý tăng lên quá nhiều dẫn đến các data pipeline trở nên vô cùng phức tạp, khiến việc quản lý và vận hành rất khó khăn. Kafka với năng lực phân phối tuyệt vời là giải pháp hoàn hảo để xử lý cho bài toán này. Tuy nhiên, để triển khai 1 hệ thống như vậy sẽ cần rất nhiều thời gian, nguồn lực, tài nguyên và chi phí.
Theo BizflyCloud - Đối tác Cloud TechData.AI.
Tham khảo Khoá đào tạo Data Engineer tại TechData.AI: https://techdata.ai/data-engineer/
Video Demo Nifi đẩy dữ liệu vào Kafka: https://youtu.be/j2DvxxhGAEs