

DATA ENGINEER ROADMAP 2025: Lộ Trình Chi Tiết Từ TechData.AI
Trong kỷ nguyên mà dữ liệu được ví như "vàng mới", vị trí của một Kỹ sư Dữ liệu (Data Engineer) trở nên quan trọng hơn bao giờ hết. Họ chính là những kiến trúc sư thầm lặng, xây dựng và duy trì nền móng vững chắc để khai thác giá trị khổng lồ từ dữ liệu. Nếu bạn đang đứng trước ngưỡng cửa của một tương lai đầy hứa hẹn, muốn khám phá con đường trở thành một Data Engineer xuất sắc vào năm 2025, bài viết này chính là kim chỉ nam dành cho bạn. TechData.AI tự hào mang đến một lộ trình chi tiết, dễ hiểu, giúp bạn vững bước trên hành trình chinh phục đỉnh cao công nghệ dữ liệu.1. Tại Sao Data Engineer Là "Kỹ Sư Trái Tim" Của Kỷ Nguyên Dữ Liệu?
 Thế giới đang chìm đắm trong một cơn lũ dữ liệu. Từ những cú nhấp chuột trên website, giao dịch mua sắm trực tuyến, cho đến các cảm biến IoT trong nhà máy thông minh, mỗi khoảnh khắc đều tạo ra hàng terabyte dữ liệu. Tuy nhiên, dữ liệu thô, rời rạc không tự nhiên mang lại giá trị. Để biến chúng thành thông tin hữu ích, phục vụ cho các quyết định kinh doanh, cần có bàn tay của những người thợ lành nghề: Kỹ sư Dữ liệu.
Data Engineer chính là người chịu trách nhiệm thiết kế, xây dựng, vận hành và tối ưu hóa các hệ thống phức tạp để thu thập, xử lý, lưu trữ và chuyển đổi dữ liệu. Họ đảm bảo rằng dữ liệu luôn sẵn sàng, sạch sẽ và có thể truy cập được cho các nhà khoa học dữ liệu (Data Scientist) phân tích, các nhà phân tích dữ liệu (Data Analyst) báo cáo, và các ứng dụng thông minh hoạt động. Họ là mạch máu, là xương sống, là "trái tim" bơm dữ liệu đến mọi ngóc ngách cần thiết trong một tổ chức.
Thế giới đang chìm đắm trong một cơn lũ dữ liệu. Từ những cú nhấp chuột trên website, giao dịch mua sắm trực tuyến, cho đến các cảm biến IoT trong nhà máy thông minh, mỗi khoảnh khắc đều tạo ra hàng terabyte dữ liệu. Tuy nhiên, dữ liệu thô, rời rạc không tự nhiên mang lại giá trị. Để biến chúng thành thông tin hữu ích, phục vụ cho các quyết định kinh doanh, cần có bàn tay của những người thợ lành nghề: Kỹ sư Dữ liệu.
Data Engineer chính là người chịu trách nhiệm thiết kế, xây dựng, vận hành và tối ưu hóa các hệ thống phức tạp để thu thập, xử lý, lưu trữ và chuyển đổi dữ liệu. Họ đảm bảo rằng dữ liệu luôn sẵn sàng, sạch sẽ và có thể truy cập được cho các nhà khoa học dữ liệu (Data Scientist) phân tích, các nhà phân tích dữ liệu (Data Analyst) báo cáo, và các ứng dụng thông minh hoạt động. Họ là mạch máu, là xương sống, là "trái tim" bơm dữ liệu đến mọi ngóc ngách cần thiết trong một tổ chức.
Phân Biệt Data Engineer Với Các Vị Trí Khác
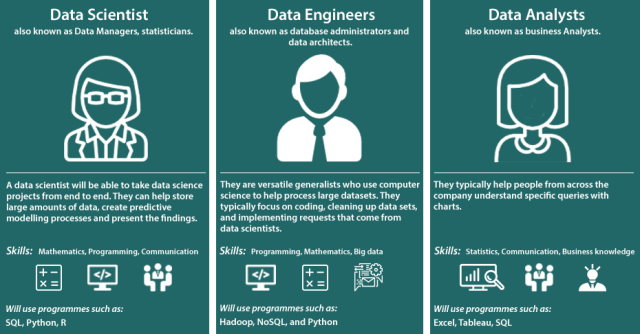
- Data Scientist (Nhà Khoa Học Dữ Liệu): Thường tập trung vào việc phân tích dữ liệu đã được xử lý, xây dựng mô hình dự đoán, và đưa ra các insight giá trị. Họ cần dữ liệu sạch và sẵn sàng, đó là lúc vai trò của Data Engineer trở nên vô cùng quan trọng. Data Engineer cung cấp "nguyên liệu" chất lượng cao để Data Scientist có thể "chế biến" ra "món ăn" ngon nhất.
- Data Analyst (Nhà Phân Tích Dữ Liệu): Chuyên về việc khám phá, diễn giải và trình bày các xu hướng, mẫu hình trong dữ liệu để hỗ trợ ra quyết định kinh doanh. Họ sử dụng dữ liệu từ các kho dữ liệu (Data Warehouse) hoặc Data Mart đã được Data Engineer xây dựng.
Nhu Cầu Thị Trường và Cơ Hội Phát Triển
Với sự bùng nổ của AI, Machine Learning và các ứng dụng dựa trên dữ liệu, nhu cầu về Data Engineer trên toàn cầu đang tăng trưởng mạnh mẽ, thậm chí còn vượt xa các vị trí khác trong lĩnh vực dữ liệu. Các công ty từ startup nhỏ đến tập đoàn đa quốc gia đều cần Data Engineer để xây dựng hạ tầng dữ liệu của họ. Mức lương của một Data Engineer thuộc hàng top trong ngành công nghệ thông tin. Tại Việt Nam và trên thế giới, mức lương khởi điểm đã rất hấp dẫn và có xu hướng tăng nhanh theo kinh nghiệm và kỹ năng chuyên sâu. Cơ hội phát triển sự nghiệp cũng rất rộng mở: từ Junior Data Engineer lên Senior, Lead, Architect, hoặc thậm chí là chuyển hướng sang DataOps Engineer, ML Ops Engineer, hoặc Product Manager chuyên về dữ liệu. Con đường này không chỉ mang lại thu nhập tốt mà còn là cơ hội để bạn làm việc với những công nghệ tiên tiến nhất, giải quyết những bài toán lớn của doanh nghiệp. Đầu tư vào kỹ năng Data Engineering là đầu tư vào một tương lai nghề nghiệp vững chắc và đầy triển vọng.2. Lộ Trình Trở Thành Data Engineer 2025: Bắt Đầu Từ Đâu?
 Để trở thành một Data Engineer giỏi, bạn cần một lộ trình học tập và rèn luyện có hệ thống. Dưới đây là lộ trình được TechData.AI thiết kế, chia thành các giai đoạn rõ ràng, giúp bạn từng bước xây dựng nền tảng và chinh phục các công nghệ phức tạp.
Để trở thành một Data Engineer giỏi, bạn cần một lộ trình học tập và rèn luyện có hệ thống. Dưới đây là lộ trình được TechData.AI thiết kế, chia thành các giai đoạn rõ ràng, giúp bạn từng bước xây dựng nền tảng và chinh phục các công nghệ phức tạp.
Giai Đoạn 1: Nền Tảng Vững Chắc (Foundation)
Đây là những kiến thức cơ bản nhất mà bất kỳ ai muốn theo đuổi ngành kỹ thuật dữ liệu cũng phải nắm vững. Chúng là bệ phóng cho những bước tiến xa hơn.- Ngôn ngữ lập trình: Python và Java/Scala
- Python: Đây là ngôn ngữ "đinh" của ngành dữ liệu. Bạn cần nắm vững cú pháp, lập trình hướng đối tượng (OOP), các thư viện xử lý dữ liệu như Pandas, NumPy, và khả năng viết script để tự động hóa các tác vụ. Python được sử dụng rộng rãi từ xây dựng ETL đến tương tác với các hệ sinh thái Big Data như Apache Spark.

- Java/Scala: Mặc dù Python đang rất phổ biến, Java hoặc Scala vẫn là những lựa chọn mạnh mẽ, đặc biệt khi làm việc với các hệ thống phân tán lớn hoặc các công cụ được xây dựng trên JVM (Java Virtual Machine) như Apache Spark (Spark Core được viết bằng Scala). Nắm vững một trong hai ngôn ngữ này sẽ mở rộng đáng kể cơ hội nghề nghiệp của bạn.
- Cơ sở dữ liệu (Database): SQL và NoSQL
- SQL (Structured Query Language): Là ngôn ngữ tiêu chuẩn để làm việc với các cơ sở dữ liệu quan hệ (Relational Databases) như PostgreSQL, MySQL, SQL Server, Oracle. Bạn cần nắm vững các câu lệnh DDL (Data Definition Language) để định nghĩa cấu trúc dữ liệu, DML (Data Manipulation Language) để thao tác dữ liệu (INSERT, UPDATE, DELETE, SELECT), JOIN, GROUP BY, subqueries, và tối ưu hóa câu truy vấn. Đây là kỹ năng không thể thiếu.
- NoSQL Databases: Khám phá các loại cơ sở dữ liệu phi quan hệ như MongoDB (Document-based), Cassandra (Column-family), Redis (Key-Value), Neo4j (Graph). Hiểu được ưu nhược điểm và khi nào nên sử dụng từng loại sẽ giúp bạn thiết kế hệ thống lưu trữ dữ liệu linh hoạt hơn.
- Hệ điều hành Linux/Unix:
- Nhiều hệ thống dữ liệu lớn và công cụ Big Data chạy trên môi trường Linux. Bạn cần làm quen với các lệnh cơ bản của Linux, cách điều hướng file hệ thống, quản lý tiến trình, scripting shell (Bash), và quản lý quyền truy cập.

- Cấu trúc dữ liệu và giải thuật (Data Structures & Algorithms):
- Hiểu biết về mảng, danh sách liên kết, cây, đồ thị, bảng băm, cùng với các giải thuật sắp xếp, tìm kiếm, sẽ giúp bạn viết mã hiệu quả hơn, tối ưu hóa hiệu suất và giải quyết các vấn đề phức tạp trong xử lý dữ liệu.
- Hệ thống kiểm soát phiên bản (Version Control System): Git/GitHub
- Kỹ năng sử dụng Git để quản lý mã nguồn, làm việc nhóm, và cộng tác trên các dự án là điều kiện tiên quyết. Nắm vững các khái niệm như commit, branch, merge, pull request là rất quan trọng.
Giai Đoạn 2: Xây Dựng Hệ Thống Dữ Liệu (Building Data Pipelines)
 Sau khi có nền tảng vững chắc, bạn sẽ bắt đầu đi sâu vào các công nghệ cốt lõi để xây dựng các đường ống dữ liệu.
Sau khi có nền tảng vững chắc, bạn sẽ bắt đầu đi sâu vào các công nghệ cốt lõi để xây dựng các đường ống dữ liệu.
- Công cụ ETL/ELT (Extract, Transform, Load / Extract, Load, Transform):
- Hiểu về các quy trình và công cụ để trích xuất dữ liệu từ các nguồn khác nhau, chuyển đổi chúng sang định dạng phù hợp, và tải vào kho đích. Bạn có thể bắt đầu với Python script đơn giản, sau đó tìm hiểu các framework như Apache Nifi, Talend, hoặc dbt (Data Build Tool) cho các quy trình ELT hiện đại.
- Hệ sinh thái Big Data: Apache Hadoop và Apache Spark
- Apache Hadoop: Mặc dù Spark đang dần thay thế, hiểu về Hadoop Distributed File System (HDFS) và MapReduce vẫn rất quan trọng để nắm bắt cách thức xử lý dữ liệu phân tán.

- Apache Spark: Đây là công cụ xử lý dữ liệu lớn "must-know". Bạn cần thành thạo Spark Core, Spark SQL, Spark Streaming, và các thư viện như PySpark (nếu dùng Python) hoặc Scala Spark (nếu dùng Scala). Spark cho phép xử lý dữ liệu nhanh chóng trong bộ nhớ và là nền tảng cho nhiều giải pháp dữ liệu hiện đại.

- Apache Hadoop: Mặc dù Spark đang dần thay thế, hiểu về Hadoop Distributed File System (HDFS) và MapReduce vẫn rất quan trọng để nắm bắt cách thức xử lý dữ liệu phân tán.
- Kho dữ liệu (Data Warehousing), Data Lake, Data Lakehouse:
- Data Warehousing: Nắm vững các khái niệm về Data Warehouse, Data Mart, mô hình chiều (Dimensional Modeling - Kimball) và mô hình chuẩn hóa (Inmon). Hiểu về OLAP (Online Analytical Processing) và OLTP (Online Transactional Processing).
- Data Lake: Học cách lưu trữ dữ liệu thô, không cấu trúc hoặc bán cấu trúc ở quy mô lớn.
- Data Lakehouse: Xu hướng mới kết hợp ưu điểm của Data Lake (linh hoạt, chi phí thấp) và Data Warehouse (cấu trúc, hiệu suất truy vấn). Tìm hiểu về các định dạng mở như Delta Lake, Apache Iceberg, Apache Hudi.

- Streaming Data (Xử lý dữ liệu thời gian thực): Apache Kafka / Kinesis
- Hiểu về khái niệm xử lý dữ liệu theo luồng (stream processing) và tại sao nó quan trọng. Nắm vững Apache Kafka là một ưu thế lớn, từ các khái niệm về producer, consumer, topic, partition cho đến Kafka Streams hoặc ksqlDB. AWS Kinesis cũng là một lựa chọn tương tự trên nền tảng Cloud.

- Hiểu về khái niệm xử lý dữ liệu theo luồng (stream processing) và tại sao nó quan trọng. Nắm vững Apache Kafka là một ưu thế lớn, từ các khái niệm về producer, consumer, topic, partition cho đến Kafka Streams hoặc ksqlDB. AWS Kinesis cũng là một lựa chọn tương tự trên nền tảng Cloud.
- Quản lý luồng công việc dữ liệu (Data Orchestration): Apache Airflow / Prefect
- Khi các đường ống dữ liệu trở nên phức tạp, bạn cần một công cụ để tự động hóa, lên lịch, giám sát và quản lý các tác vụ. Apache Airflow là công cụ phổ biến nhất, cho phép bạn định nghĩa các DAG (Directed Acyclic Graphs) để điều phối workflow dữ liệu một cách hiệu quả.
Giai Đoạn 3: Triển Khai và Tối Ưu Hóa Trên Đám Mây (Cloud Deployment & Optimization)
Điện toán đám mây là tương lai của hạ tầng dữ liệu. Việc thành thạo ít nhất một nền tảng Cloud là điều kiện cần để trở thành một Data Engineer hiện đại.- Các nền tảng Cloud: AWS, Google Cloud Platform (GCP), Microsoft Azure
- Chọn một nền tảng để học chuyên sâu, ví dụ như AWS. Hiểu về các dịch vụ cốt lõi liên quan đến dữ liệu:
- AWS: S3 (lưu trữ), EC2 (máy ảo), Lambda (serverless compute), RDS (cơ sở dữ liệu quan hệ), Redshift (data warehouse), EMR (Spark/Hadoop trên cloud), Glue (ETL serverless), Kinesis (streaming), Athena (truy vấn S3).

- GCP: Cloud Storage, Compute Engine, Cloud Functions, BigQuery (data warehouse), Dataproc (Spark/Hadoop), Dataflow (streaming/batch processing), Pub/Sub (messaging).

- Azure: Azure Blob Storage, Azure Virtual Machines, Azure Functions, Azure SQL Database, Azure Synapse Analytics, Azure Databricks, Azure Data Factory, Azure Event Hubs.

- DevOps và CI/CD cho Data Pipelines:
- Áp dụng các nguyên tắc DevOps và Continuous Integration/Continuous Delivery (CI/CD) vào phát triển và triển khai đường ống dữ liệu. Sử dụng công cụ như Jenkins, GitLab CI/CD, GitHub Actions để tự động hóa quy trình kiểm thử, triển khai mã nguồn.
- Quản trị dữ liệu (Data Governance), Chất lượng dữ liệu (Data Quality), Bảo mật dữ liệu (Data Security):
- Hiểu về tầm quan trọng của việc quản lý vòng đời dữ liệu, đảm bảo dữ liệu sạch, chính xác và được bảo mật theo các quy định pháp lý (GDPR, HIPAA). Đây là những khía cạnh quan trọng đối với một Data Engineer cấp cao.
Giai Đoạn 4: Phát Triển Kỹ Năng Mềm và Kinh Nghiệm Thực Chiến (Soft Skills & Practical Experience)
Kiến thức chuyên môn là chưa đủ. Kỹ năng mềm và kinh nghiệm thực tế sẽ là yếu tố quyết định sự thành công của bạn.- Kỹ năng giải quyết vấn đề và tư duy logic:
- Data Engineering là ngành đòi hỏi khả năng phân tích vấn đề phức tạp, chia nhỏ và tìm ra giải pháp tối ưu.
- Kỹ năng giao tiếp và làm việc nhóm:
- Bạn sẽ phải thường xuyên làm việc với Data Scientist, Data Analyst, Product Manager và các bộ phận khác. Giao tiếp hiệu quả là chìa khóa để hiểu yêu cầu và truyền đạt giải pháp.
- Thực hiện các dự án cá nhân và tham gia mã nguồn mở:
- Áp dụng kiến thức vào các dự án nhỏ của riêng bạn (ví dụ: xây dựng một pipeline ETL từ API công cộng, xử lý dữ liệu từ mạng xã hội). Tham gia đóng góp vào các dự án mã nguồn mở liên quan đến dữ liệu cũng là cách tuyệt vời để học hỏi và xây dựng kinh nghiệm.
- Xây dựng portfolio và CV ấn tượng:
- Tài liệu hóa các dự án bạn đã làm, những vấn đề bạn đã giải quyết và công nghệ bạn đã sử dụng. Đây là bằng chứng tốt nhất cho năng lực của bạn khi tìm việc.
3. Những Công Nghệ "Must-Know" Của Data Engineer Hiện Đại (2025)
Trong lộ trình đã đề cập, có một số công nghệ nổi bật mà một Data Engineer muốn thành công trong năm 2025 không thể bỏ qua. Chúng đại diện cho xu hướng phát triển mạnh mẽ nhất trong ngành.- Python và SQL: Nền Tảng Không Thể ThiếuHai ngôn ngữ này là "bánh mì và bơ" của Data Engineer. Python với sự linh hoạt, hệ sinh thái thư viện khổng lồ (Pandas, NumPy, PySpark) cho phép bạn thực hiện mọi thứ từ thu thập dữ liệu, xử lý, đến tự động hóa. SQL vẫn là ngôn ngữ bất di bất dịch để tương tác với cơ sở dữ liệu quan hệ, nơi lưu trữ phần lớn dữ liệu kinh doanh quan trọng.
- Apache Spark: Sức Mạnh Xử Lý Dữ Liệu LớnSpark đã trở thành tiêu chuẩn vàng cho việc xử lý dữ liệu lớn (Big Data). Khả năng xử lý trong bộ nhớ, tính toán phân tán hiệu quả, cùng với các API dễ sử dụng cho nhiều ngôn ngữ (Scala, Python, Java, R) giúp Spark vượt trội hơn hẳn các công nghệ cũ như MapReduce. Nắm vững Spark, đặc biệt là Spark SQL và PySpark, sẽ mở ra vô số cơ hội.
- Các Nền Tảng Cloud (AWS, GCP, Azure): Sự Chuyển Dịch Tất YếuNgày càng nhiều doanh nghiệp chuyển dịch hạ tầng dữ liệu lên đám mây để tận dụng khả năng mở rộng, chi phí hiệu quả và các dịch vụ quản lý. Việc thông thạo ít nhất một nền tảng Cloud và các dịch vụ dữ liệu chuyên biệt của nó (như AWS S3, Redshift, EMR, Glue; GCP BigQuery, Dataproc, Dataflow; Azure Synapse, Databricks, Data Factory) là bắt buộc. Hiểu về kiến trúc serverless cũng là một lợi thế lớn.
- Công Cụ Orchestration (Apache Airflow): Tự Động Hóa Dòng Chảy Dữ LiệuKhi các đường ống dữ liệu phức tạp hơn, việc quản lý và lên lịch cho chúng trở thành một thách thức. Airflow giúp bạn định nghĩa, lên lịch và giám sát các quy trình ETL/ELT một cách trực quan thông qua mã Python. Nó trở thành trung tâm điều khiển cho toàn bộ hệ thống dữ liệu của bạn, đảm bảo các tác vụ chạy đúng thời điểm, đúng trình tự và thông báo khi có lỗi.
- Data Lakehouse (Delta Lake, Apache Iceberg, Apache Hudi): Xu Hướng Mới Của NgànhMô hình Data Lakehouse đang là một trong những xu hướng nóng nhất. Nó kết hợp tính linh hoạt của Data Lake với cấu trúc và hiệu suất của Data Warehouse, cho phép cả phân tích dữ liệu batch và streaming trên cùng một nền tảng. Các định dạng mở như Delta Lake (Databricks), Apache Iceberg, và Apache Hudi cung cấp các tính năng như ACID transactions, schema enforcement, time travel trên Data Lake, mang lại sự tin cậy và hiệu suất cao cho dữ liệu lớn.
- Apache Kafka: Xử Lý Dữ Liệu Thời Gian ThựcTrong thế giới số, nhu cầu xử lý dữ liệu ngay lập tức (real-time data) ngày càng tăng. Kafka là một nền tảng streaming phân tán hàng đầu, được sử dụng để xây dựng các đường ống dữ liệu thời gian thực và ứng dụng streaming. Hiểu về Kafka và cách xây dựng các pipeline streaming sẽ giúp bạn xử lý những tình huống yêu cầu dữ liệu tức thì, như hệ thống khuyến nghị, phát hiện gian lận hay phân tích log trực tiếp.
4. Vượt Qua Thử Thách: Lời Khuyên Từ Chuyên Gia TechData.AI
Hành trình trở thành một Data Engineer không phải lúc nào cũng trải đầy hoa hồng. Sẽ có những lúc bạn cảm thấy choáng ngợp trước lượng kiến thức khổng lồ và tốc độ thay đổi nhanh chóng của công nghệ. Tuy nhiên, với niềm đam mê và phương pháp đúng đắn, bạn hoàn toàn có thể vượt qua mọi thử thách.- Học Tập Liên Tục và Thích Nghi Nhanh Chóng:Ngành công nghệ dữ liệu phát triển không ngừng. Những công cụ hôm nay có thể trở nên lỗi thời vào ngày mai. Hãy luôn giữ tinh thần học hỏi, cập nhật kiến thức mới, và sẵn sàng thích nghi với các công nghệ mới nổi. Đọc blog ngành, tham gia webinar, và theo dõi các chuyên gia hàng đầu là cách hiệu quả.
- Không Ngại Thất Bại, Quan Trọng Là Học Hỏi Từ Chúng:Trong quá trình xây dựng hệ thống dữ liệu, bạn chắc chắn sẽ gặp lỗi, pipeline bị hỏng hoặc hiệu suất không như mong muốn. Đừng nản lòng. Mỗi lỗi lầm đều là một bài học quý giá. Hãy phân tích nguyên nhân, tìm giải pháp, và ghi nhớ để tránh lặp lại. Đây là cách nhanh nhất để bạn trưởng thành.
- Xây Dựng Mạng Lưới và Kết Nối Với Cộng Đồng:Tham gia các diễn đàn trực tuyến, cộng đồng Data Engineering trên LinkedIn, Facebook, hoặc các buổi meetup offline. Chia sẻ kiến thức, đặt câu hỏi, và học hỏi từ kinh nghiệm của người khác. Một mạng lưới rộng lớn sẽ mang lại cho bạn những cơ hội bất ngờ và sự hỗ trợ khi cần thiết.
- Tìm Mentor và Học Hỏi Từ Người Đi Trước:Nếu có thể, hãy tìm một người mentor đã có kinh nghiệm trong lĩnh vực Data Engineering. Họ có thể cung cấp lời khuyên quý báu, chia sẻ kinh nghiệm thực tế và giúp bạn định hướng sự nghiệp. Học hỏi từ những người đi trước sẽ giúp bạn tiết kiệm thời gian và tránh được nhiều sai lầm.
- Bắt Đầu Ngay Hôm Nay:Không có thời điểm nào tốt hơn để bắt đầu hành trình của bạn ngoài ngay bây giờ. Dù bạn là sinh viên, người mới bắt đầu sự nghiệp hay muốn chuyển ngành, hãy vạch ra lộ trình, bắt tay vào học tập và thực hành. Mỗi dòng code bạn viết, mỗi khái niệm bạn nắm vững đều là một bước tiến nhỏ nhưng quan trọng.