

Trong thời đại dữ liệu lớn, các tổ chức vừa đến lớn đều phụ thuộc vào khả năng xử lý khối lượng dữ liệu khổng lồ cho các ứng dụng thời gian thực. Apache Spark xuất hiện như một giải pháp toàn diện, hiệu quả cho các nhu cầu phân tích và xử lý dữ liệu. Ngay từ khi ra đời, Apache Spark đã nhanh chóng được các doanh nghiệp trong nhiều lĩnh vực ứng dụng rộng rãi, đặc biệt là các “ông lớn” công nghệ để đẩy mạnh khả năng khai thác dữ liệu lớn.
Apache Spark là gì?

Apache Spark là một framework xử lý dữ liệu mã nguồn mở trên quy mô lớn. Spark cung cấp một giao diện để lập trình các cụm tính toán song song với khả năng chịu lỗi. Ban đầu Spark được phát triển tại AMPLab của Đại học California Berkeley, sau đó mã nguồn được tặng cho Apache Software Foundation vào năm 2013 và tổ chức này đã duy trì nó cho đến nay.
Khả năng tính toán phân tán của Apache Spark khiến nó rất phù hợp với big data và machine learning, vốn đòi sức mạnh tính toán khổng lồ để làm việc trên các kho dữ liệu lớn. Spark cũng giúp loại bỏ một số gánh nặng lập trình khỏi vai của các nhà phát triển với một API dễ sử dụng đảm nhiệm phần lớn công việc khó khăn của tính toán phân tán và xử lý dữ liệu lớn.

Các thành phần của Apache Spark
Apache Spark gồm có 5 thành phần chính: Spark Core, Spark Streaming, Spark SQL, MLlib và GraphX.
Như tên gọi, Spark Core là thành phần cốt lõi của Apache Spark, các thành phần khác muốn hoạt động đều cần thông qua Spark Core. Spark Core có vai trò thực hiện công việc tính toán và xử lý trong bộ nhớ (In-memory computing), đồng thời nó cũng tham chiếu đến các dữ liệu được lưu trữ tại các hệ thống lưu trữ bên ngoài.
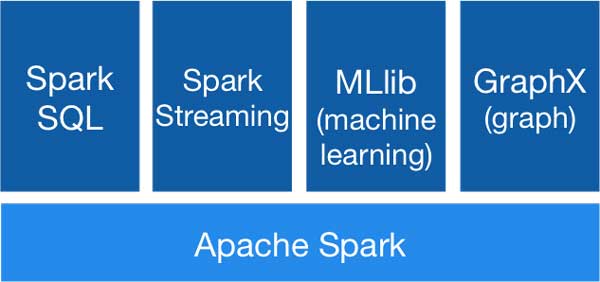
Spark SQL
Spark SQL tập trung vào việc xử lý dữ liệu có cấu trúc, sử dụng phương pháp tiếp cận khung dữ liệu được mượn từ các ngôn ngữ R và Python (trong Pandas). Như tên gọi, Spark SQL cũng cung cấp giao diện với cú pháp SQL để truy vấn dữ liệu, mang sức mạnh của Apache Spark đến các nhà phân tích dữ liệu cũng như các nhà phát triển.
Bên cạnh khả năng hỗ trợ SQL, Spark SQL cung cấp một giao diện tiêu chuẩn để đọc và ghi vào các kho dữ liệu khác bao gồm JSON, HDFS, Apache Hive, JDBC, Apache ORC và Apache Parquet, tất cả đều được hỗ trợ trực tiếp. Các cơ sở dữ liệu phổ biến khác như Apache Cassandra, MongoDB, Apache Hbase,… cũng được hỗ trợ thông qua các trình kết nối riêng biệt từ hệ sinh thái Spark Packages.
Spark Streaming
Spark Streaming là một bổ sung ban đầu cho Apache Spark giúp nó đáp ứng các yêu cầu xử lý thời gian thực (realtime) hoặc gần như thời gian thực. Spark Streaming chia nhỏ luồng xử lý thành một chuỗi liên tục gồm các microbatch mà sau đó có thể được thao tác bằng API Apache Spark.
Bằng cách này, mã trong các xử lý hàng loạt và trực tuyến có thể được tái sử dụng, chạy trên cùng một framework, do đó giảm chi phí cho cả nhà phát triển và nhà điều hành.
MLlib (Machine Learning Library)
MLlib là một nền tảng học máy phân tán bên trên Spark với kiến trúc phân tán dựa trên bộ nhớ. Theo các một số so sánh, Spark MLlib nhanh hơn 9 lần so với thư viện tương đương chạy trên Hadoop là Apache Mahout.
GrapX
Spark GraphX đi kèm với lựa chọn các thuật toán phân tán để xử lý cấu trúc đồ thị. Các thuật toán này sử dụng phương pháp tiếp cận RDD của Spark Core để lập mô hình dữ liệu; gói GraphFrames cho phép bạn thực hiện các xử lý biểu đồ trên khung dữ liệu, bao gồm cả việc tận dụng trình tối ưu hóa Catalyst cho các truy vấn đồ thị.
Kiến trúc của Apache Spark
Về cơ bản, Apache Spark bao gồm hai thành phần chính: trình điều khiển (driver) và trình thực thi (executors). Trình điều khiển dùng để chuyển đổi mã của người dùng thành nhiều tác vụ (tasks) có thể được phân phối trên các nút xử lý (worker nodes).
Trình thực thi chạy trên các nút xử lý và thực hiện các nhiệm vụ được giao cho chúng. Spark cũng có thể chạy ở chế độ cụm độc lập chỉ yêu cầu khung Apache Spark và JVM trên mỗi máy trong cụm. Tuy nhiên, sử dụng các công cụ quản lý cụm như trung gian giữa hai thành phần giúp tận dụng tài nguyên tốt hơn và cho phép phân bổ theo yêu cầu. Trong doanh nghiệp, Apache Spark có thể chạy trên Apache Mesos, Kubernetes và Docker Swarm.
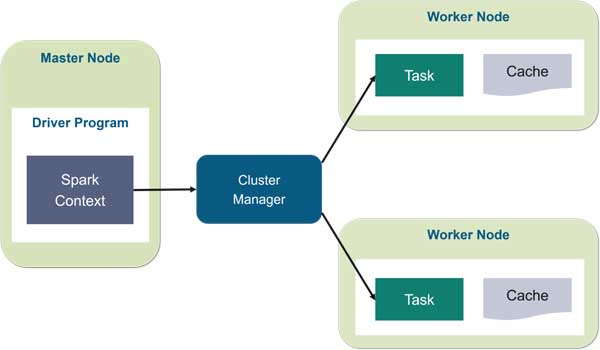
Apache Spark xây dựng các lệnh xử lý dữ liệu của người dùng thành Đồ thị vòng có hướng hoặc DAG. DAG là lớp lập lịch của Apache Spark; nó xác định những tác vụ nào được thực thi trên những nút nào và theo trình tự nào.
Apache Spark có những ưu điểm gì?
Tốc độ cao
Được thiết kế từ dưới lên để tăng hiệu suất, Spark có thể nhanh hơn 100 lần so với Hadoop khi xử lý dữ liệu quy mô lớn bằng cách khai thác tính toán trên bộ nhớ và các tối ưu hóa khác. Spark cũng nhanh khi dữ liệu được lưu trữ trên đĩa và hiện đang giữ kỷ lục thế giới về phân loại trên đĩa quy mô lớn.
Dễ sử dụng
Spark có các API dễ sử dụng để làm việc trên các tập dữ liệu lớn, bao gồm hơn 100 toán tử để chuyển đổi dữ liệu và các API dataframe quen thuộc để xử lý dữ liệu bán cấu trúc.
Thư viện hỗ trợ rộng
Spark được đóng gói với các thư viện cấp cao, bao gồm hỗ trợ truy vấn SQL, truyền dữ liệu trực tuyến, học máy và xử lý đồ thị. Các thư viện tiêu chuẩn này làm tăng năng suất của nhà phát triển và có thể được kết hợp liền mạch để tạo ra các quy trình làm việc phức tạp.
Tham khảo khoá đào tạo Data Engineer tại TechData.AI - Link
